Sự khác biệt giữa 100 hàng dữ liệu và 100 ngàn hay thậm chí là một triệu hàng dữ liệu là rất nhiều! Ừ ai chả biết!
Vấn đề ở đây là với dữ liệu lớn bạn không thể thao tác thủ công được. Bạn sẽ phải viết mã để chạy tự động. Và nếu mã không hiệu quả, thiết bị mà bạn chạy ứng dụng có thể không kham nổi.
Các kinh nghiệm trong bài viết này được tôi rút ra khi phân tích một bảng dữ liệu họ tên có hơn 240 ngàn hàng. Bảng này bao gồm 3 cột dữ liệu là họ tên (hoten), ngày tháng năm sinh (ngay) và giới tính (gioi).
Chuẩn hóa dữ liệu
Dữ liệu lớn thường thu nhập từ nhiều nguồn, hoặc được nhập từ nhiều người. Điều đó dẫn đến tính trạng dữ liệu không được đồng bộ, ví dụ:
- Ngày tháng năm được viết bởi nhiều định dạng như dd/mm/yy, dd/mm/yyyy, mm/dd/yyyy, vân vân;
- Tiếng Việt với các ký tự có dấu như ễ, ó, ừ, v.v.. có thể được mã hóa thành 2 dạng khác nhau, dẫn đến việc câu lệnh PHP để thống kê sai sót;
- Dữ liệu có sai sót, chẳng hạn như dữ liệu giới tính của người bị thiếu, trong khi đáng ra phải có. Họ tên có các ký tự không phải chữ cái;
Các điều không nên làm
- Lập trình trực tiếp trên giao diện máy chủ web hosting để thao tác lệnh
Điều này nghe có vẻ ngớ ngẩn, nhưng tôi đã từng viết lệnh trực tiếp qua giao diện quản trị của control panel hosting! Và ngay cả với VPS Vultr 4GB 2CPU, tốc độ thực thi lệnh vẫn kém xa máy tính bàn / laptop có chất lượng tốt. Và tất nhiên thực hiện qua môi trường máy tính cá nhân bạn còn không tốn tiền.
XAMPP + Apache Netbeans + JDK SE (cần khi bạn cài Netbeans) là đủ cho chúng ta, tất cả đều miễn phí, cài đặt đơn giản. Dĩ nhiên giao diện viết mã của Netbeans tốt hơn nhiều giao diện của control panel hosting.
2. Viết mã PHP xử lý dữ liệu quá cẩn thận
Chúng ta có khuynh hướng viết mã xử lý tổng quát, bao trùm nhiều trường hợp. Đây là tư duy nhìn chung là tốt, vì nó sẽ giúp chúng ta phát triển kỹ năng và xử lý chính xác trong nhiều bối cảnh dữ liệu.
Nhưng cần sử dụng điều này một cách hợp lý, vì nó sẽ dẫn đến xử lý quá tải hoặc rất chậm.
Chẳng hạn để xử lý trường dữ liệu giới tính mà tiêu chuẩn chỉ bao gồm dữ liệu là nam và nữ, tôi từng nghĩ cách xử lý như sau:
- Loại bỏ khoảng trắng có trong dữ liệu bằng hàm
trimvàpreg_replace; - Loại bỏ các ký tự không phải văn bản bằng cách chạy một mảng các ký tự không phải văn bản kết hợp với hàm
str_replace. Đây là câu lệnh tốn thời gian vì một dữ liệu qua đây sẽ phải chạy qua mảng gồm gần 20 phần tử; - Chuyển ký từ về dạng viết thường bằng hàm
mb_strtolower;
Điều dở ở đây là mặc dù dữ liệu lớn, nhưng vì cột giới tính dữ liệu rất đơn giản, nên thực tế vấn đề “có các ký tự không phải văn bản” hóa ra KHÔNG xảy ra trong bất cứ hàng nào trong hơn 240 ngàn hàng dữ liệu mà tôi có.
Nói cách khác việc viết câu lệnh tốn thời gian thực thi nhất là hoàn toàn vô ích. Vậy nếu dữ liệu không cần sửa thì chúng ta không nên viết mã sửa làm gì.
Để làm được điều đó, chúng ta cần phải xác định được mức độ sai lệch dữ liệu của chúng ta đang ở mức nào, để các dòng lệnh không cần phải thực thi những nhiệm vụ không cần thiết.
Một trong những cách đơn giản nhất để làm điều này là sử dụng câu lệnh nhóm các phần tử giống nhau để phát hiện các trường dữ liệu bất thường, điều này đặc biệt phù hợp với các cột dữ liệu có rất nhiều phần tử nhưng dạng cụ thể của phần tử thì giới hạn. Chẳng hạn giới chỉ có 2 dạng cụ thể là nam và nữ. Họ người Việt cũng chỉ giới hạn trong số lượng nhất định (cỡ khoảng vài trăm).
Câu lệnh SQL để bạn nhóm các dữ liệu giống nhau là:
SELECT * , COUNT(*) AS number_record
FROM ten_bang
GROUP BY ten_cot_du_lieu_can_nhom
HAVING number_record > 0Kết quả của tôi như sau:
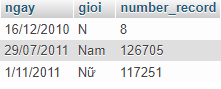
Tức là thực tế cho thấy dữ liệu được nhập vào rất tốt, chỉ có 8 hàng nhập sai với chỉ ký tự N.
Cẩn thận hơn bạn có thể viết mã đơn giản để thống kê trực tiếp, ví dụ trong trường hợp trên tôi sẽ dùng câu lệnh PHP sau để biết được mức độ sai lệch dữ liệu ở mức nào:
session_start();
ob_start();
require 'database.php'; // tai database
$query3="SELECT gioi FROM hoten";
$result3=$db->query($query3);
$nam=0;
$nu=0;
$sai=0;
$mangsai=array();
$hdl=0;
foreach ($result3 as $value3) {
if ($value3['gioi']=="Nam" || $value3['gioi']=="nam") {$nam++;} else {
if ($value3['gioi']=="Nữ" || $value3['gioi']=="nữ") {$nu++;} else {$mangsai[$sai]=$value3['gioi'];$sai++;}
}
$hdl++;
}
$tong = $nam + $nu + $sai;
echo "Nam: ".$nam;
echo "</br>";
echo "Nữ: ".$nu;
echo "</br>";
echo "Sai dữ liệu: ".$sai;
echo "</br>";
echo "Tổng Nam + Nữ + Sai dữ liệu: ".$tong;
echo "</br>";
echo "Số hàng dữ liệu: ".$hdl;
echo "</br>";
echo "Các dữ liệu sai lệch:";
echo "</br>";
for ($i=0;$i<$sai;$i++) {
echo $mangsai[$i]."</br>";
}Kết quả:


Điều đó cho thấy tôi không cần phải phức tạp hóa đoạn mã xử lý cột giới tính, chỉ cần chuyển nó về dạng viết thường là đủ.
3. Không biết dùng regular expression
Ở thời điểm hiện tại tôi cũng chưa thành thạo regular expression lắm, nhưng khi mới thử tìm hiểu mới thấy sức mạnh của nó.
Không biết regular expression bạn có thể phải viết vài chục dòng mã cồng kềnh, còn nếu biết bạn có cơ hội chỉ phải viết một dòng mà thôi!
Ví dụ đây là đoạn mã cồng kềnh tôi dùng để phát hiện một dữ liệu ngày tháng năm không phải là dạng dd/mm/yyyy
preg_match('/[a-z]/', '$ngaythangnam', $matches1); // dùng để kiểm tra có ký tự abc,..xyz trong dữ liệu ngày tháng năm hay không
if (count($matches1) > 0) {echo "có lỗi 1";}
echo "</br>";
$kytuloi = array('?',')', '(', '[', ']', '{', '}', '.', ',', '"', ':', ';', '~', '!', '@', '#', '%', '^', '&', '*', '+', '=', '-', '_', '>', '<'); //
$t = count($kytuloi);
$loi=array();
for ($i=0;$i<$t;$i++) {
$l=mb_strpos($ngaythangnam,$kytuloi[$i]);
if ($l>0) {$loi[$i]=1;}
}
if (count($loi) > 0) {echo 'có lỗi 2';} //dùng để kiểm tra có các ký tự đặc biệt trong dữ liệu ngày tháng hay không
$gach=substr_count('$ngaythangnam', '/');
if ($gach!=2) {echo 'có lỗi 3';} //dùng để kiểm tra dữ liệu có phải là dạng phân cách nhau bằng dấu / và có đủ 2 dấu hay khôngTrong khi đó chỉ với một dòng lệnh sau, tôi sẽ biết được dữ liệu có hợp chuẩn hay không:
preg_match('/\b\d{1,2}\/\d{1,2}\/\d{4}\b/', $ngaythangnam, $matches);Cụm \b\d{1,2}\/\d{1,2}\/\d{4}\b chính là cái giúp chúng ta không phải viết quá nhiều mã. Nó nói rằng dữ liệu cần phải phân cách bằng dấu / với dạng như sau 1 hoặc 2 ký tự số / 1 hoặc 2 ký tự số / phải có 4 ký tự số. Đây chính là định dạng dd/mm/yyyyy của chúng ta.
4. Không sử dụng tính năng Search / Tìm kiếm trong SQL
Tính năng này giúp chúng ta kiểm tra rất nhanh các dữ liệu lệch chuẩn thay vì phải ngồi viết lệnh PHP.
Một số toán tử quan trọng bao gồm:
- Toán tử = để so khớp chính xác;
- Toán tử is NULL để phát hiện dữ liệu NULL / Không có dữ liệu;
- Biểu thức chính quy REGEXP, đó chính là regular expression;
Thực tế hình thức tìm kiếm nào bạn dùng còn phụ thuộc vào kiểu dữ liệu của bạn. Ở trên chỉ là kinh nghiệm riêng với dữ liệu họ tên mà tôi cần thao tác.
Ví dụ với dữ liệu ngày tháng năm sinh, tôi thử dùng \b\d{1,2}\/\d{1,2}\/\d{4}\b trong SQL thì kết quả cho thấy tất cả dữ liệu khác NULL đều hợp chuẩn.
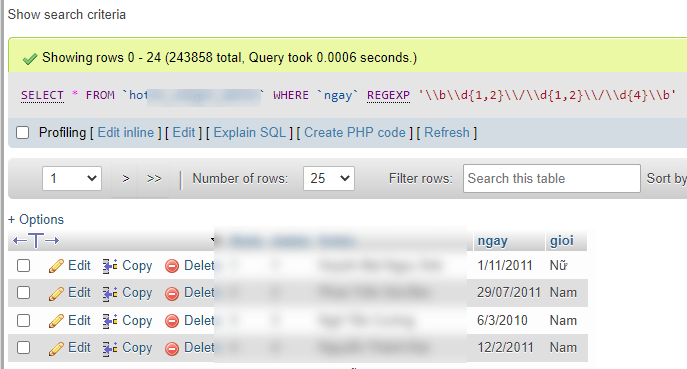
Điều này một lần nữa giúp tôi biết được rằng mình không cần phải viết hàm xử lý ngày tháng phức tạp.
5. Sử dụng bộ mã utf8_general_ci
utf8_general_ci là bộ mã không hiệu quả để sắp xếp, phân tích dữ liệu trong SQL. Với kiểu mã hóa khác nhau của tiếng Việt, utf8_general_ci sẽ đưa ra các kết quả không như ý.
Bộ mã tốt hơn mà bạn nên dùng là utf8mb4_unicode_ci
6. Để thời gian thực hiện lệnh PHP theo mặc định
Mặc định có thể là 120 giây, tuy nhiên trên các ứng dụng xử lý dữ liệu lớn, thời gian này không đủ. Với lượng data gồm 240 ngàn dữ liệu, tôi có thể cần đến 5 phút để chạy lệnh.
Cách để bạn nâng con số này lên là thêm dòng sau vào file .php mà bạn cần thực thi:
set_time_limit(600); // tương đương với 10 phút = 600 giây7. Chia dữ liệu ra để xử lý
Trong trường hợp áp dụng mọi cách mà việc xử lý dữ liệu vẫn quá tải thì bạn nên chia nhỏ dữ liệu ra.
Việc chia nhỏ có thể dùng một trong 2 cách sau:
- Bạn chia làm nhiều bảng dữ liệu;
- Bạn sử dụng câu lệnh điều kiện WHERE trong SQL để SELECT giới hạn một số lượng bản ghi nhất định, thay vì chọn toàn bộ bản ghi trong bảng;